Human Visual Attention Model based on Analysis of Magic for Smooth Human-Robot Interaction
概要
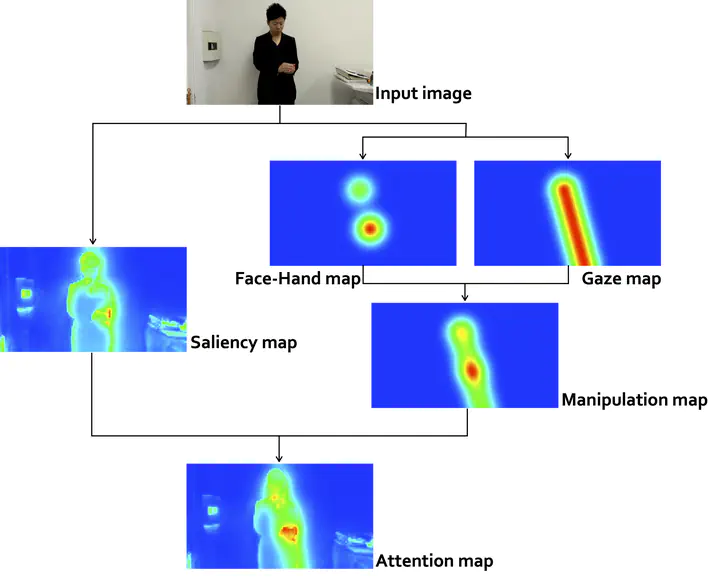
In order to smoothly interact with humans, it is desirable that a robot can guide human attention and behaviors. In this study, we developed a model of human visual attention for guiding human attention based on an analysis of a magic trick performance. We measured human gaze points of people watching a video of a magic trick performance and compared them with the area where the magician intended to draw a spectator’s attention. The analysis showed that the relationship between the magician’s face, hands, and gaze plays an important role in guiding the spectator’s attention. On the basis of the preliminary user studies on watching the magic video, we integrated a saliency map and a manipulation map that describes the relationship between gaze and hands to develop a novel human attention model. The evaluation using the observed gaze points demonstrated that the proposed model can better explain human visual attention than the saliency map while people are watching a video of a magic trick performance.