概要
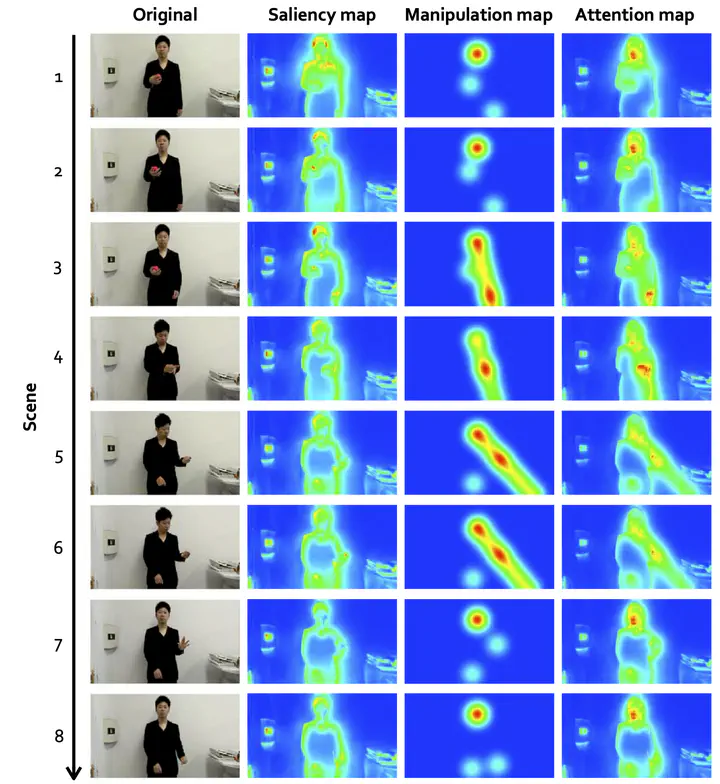
For smooth interaction between human and robot, the robot should have an ability to manipulate human attention and behaviors. In this study, we developed a visual attention model for manipulating human attention by a robot. The model consists of two modules, such as the saliency map generation module and manipulation map generation module. The saliency map describes the bottom-up effect of visual stimuli on human attention and the manipulation map describes the top-down effect of face, hands and gaze. In order to evaluate the proposed attention model, we measured human gaze points during watching a magic video, and applied the attention model to the video. Based on the result of this experiment, the proposed attention model can better explain human visual attention than the original saliency map.